Як налаштувати синтез мови в UniTalk: покроковий гайд
Потреба у швидкій персоналізації та оновленні голосових повідомлень більше не обмежується часом на студійний запис чи бюджетом на диктора. Синтез мови (Text-to-Speech, TTS) від UniTalk — це інтелектуальний інструмент, який миттєво генерує аудіо з вашого тексту, імітуючи людську мову з інтонаціями та паузами. Це дає вам можливість швидко створювати десятки унікальних вітань, оновлювати IVR-меню та масово обдзвонювати клієнтів з максимальною натуральністю звучання. Ознайомтеся з нашими гнучкими інструментами та порівняйте провідних провайдерів (включно з UniTalk Alfa), щоб ваш голос звучав бездоганно.
1. Синтез мови на сторінці “Синтез аудіо”
У розділі “Синтез аудіо” в особистому кабінеті Ви можете створювати власні аудіо файли з тексту одразу додаючи їх в необхідний Вам функціонал: у вхідні сценарії, голосове меню, обдзвони, мелодії очікування в черзі з супроводженням, в АРІ дзвінках.
Текст, який Ви бажаєте перевести в аудіо, може бути як у звичайному форматі, так і в форматі SSML.
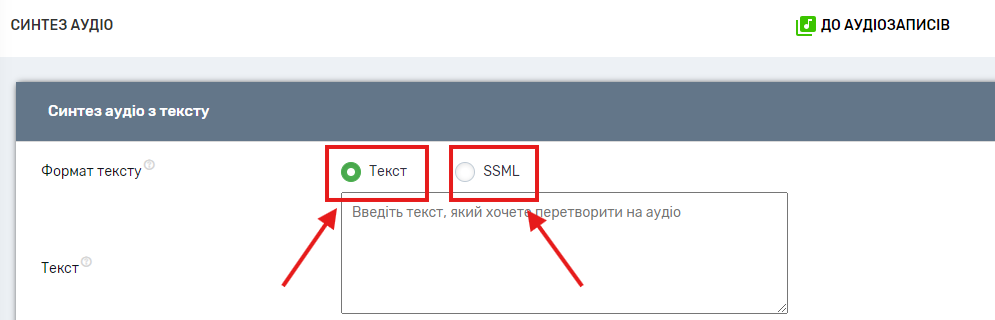
SSML (Speech Synthesis Markup Language) – мова розмітки для додатків синтезу мови, що дозволяє більш тонко налаштувати озвучування тексту.
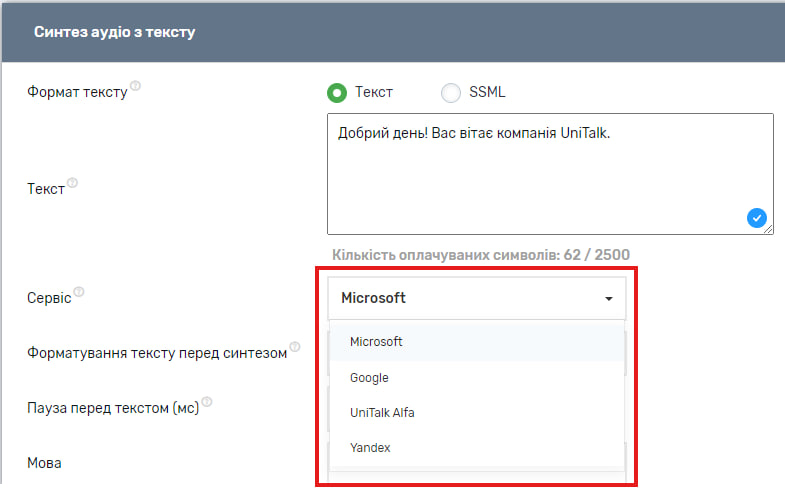
Також можна обрати сервіс через який буде синтезуватися мова. У списку доступних наразі сервіси від Microsoft, Google, UniTalk Alfa, Yandex.
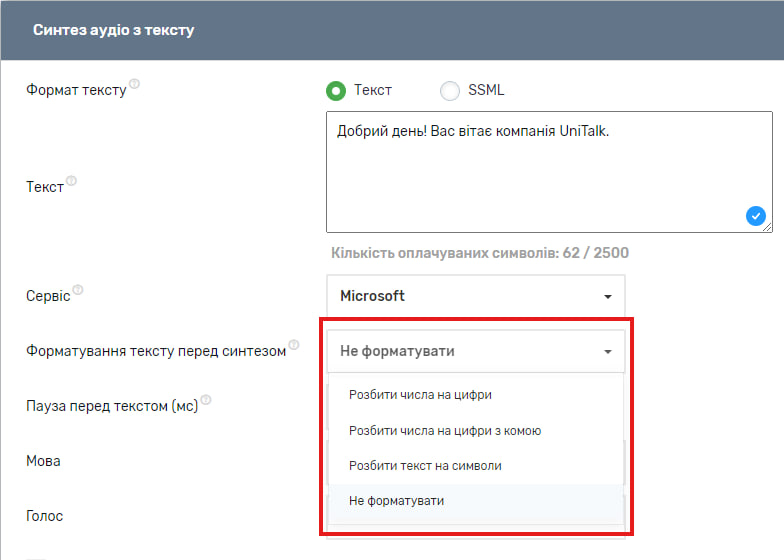
Крім того, є можливість відформатувати текст перед синтезом. У форматування входить розбиття числа на цифри або на цифри з комою, розбиття тексту на символи. Налаштування не працює для синтезу тексту у форматі SSML. Також варто зазначити, що тип форматування впливатиме на кількість оплачуваних символів.
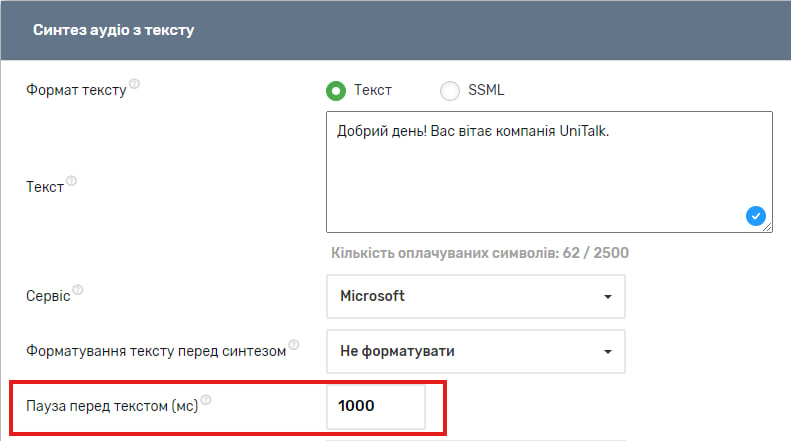
Ось тут можна вибрати паузу перед текстом, яка вимірюється в мілісекундах. 1 секунда = 1000 мілісекунд. Тривалість паузи також впливає на кількість оплачуваних символів.
Також є можливість обрати мову, якою буде озвучений введений Вами текст.
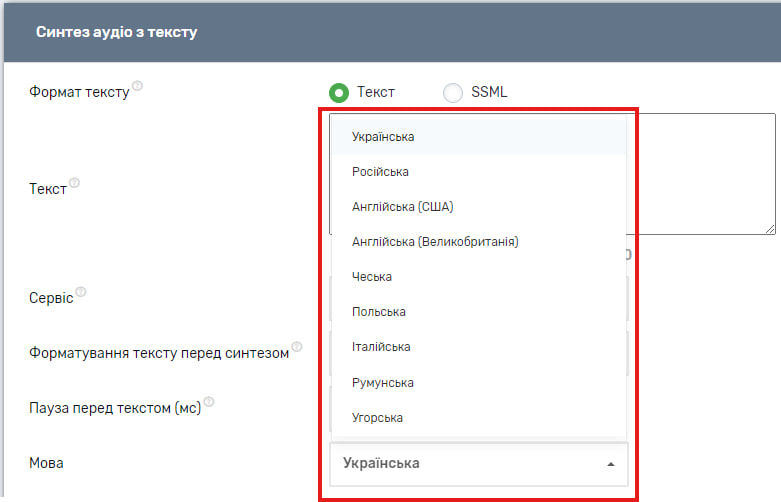
І варіант голосу, яким буде озвучений текст.
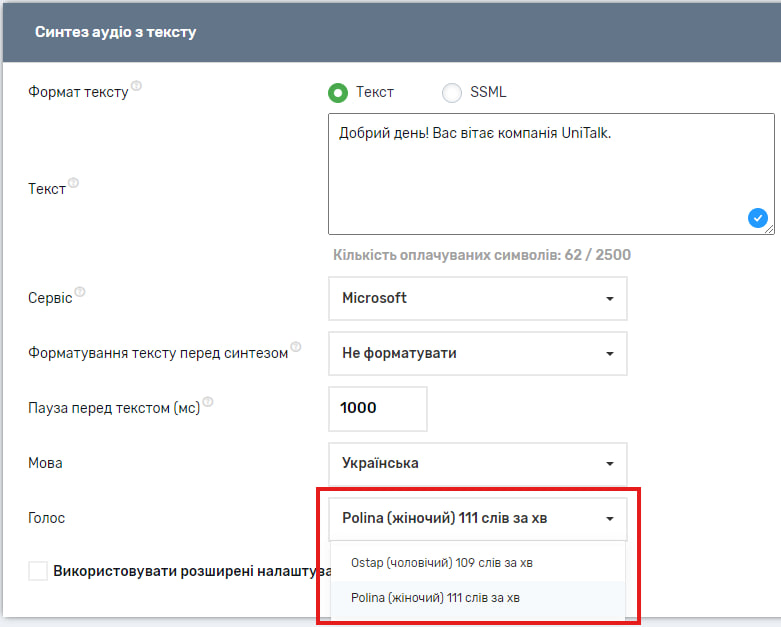
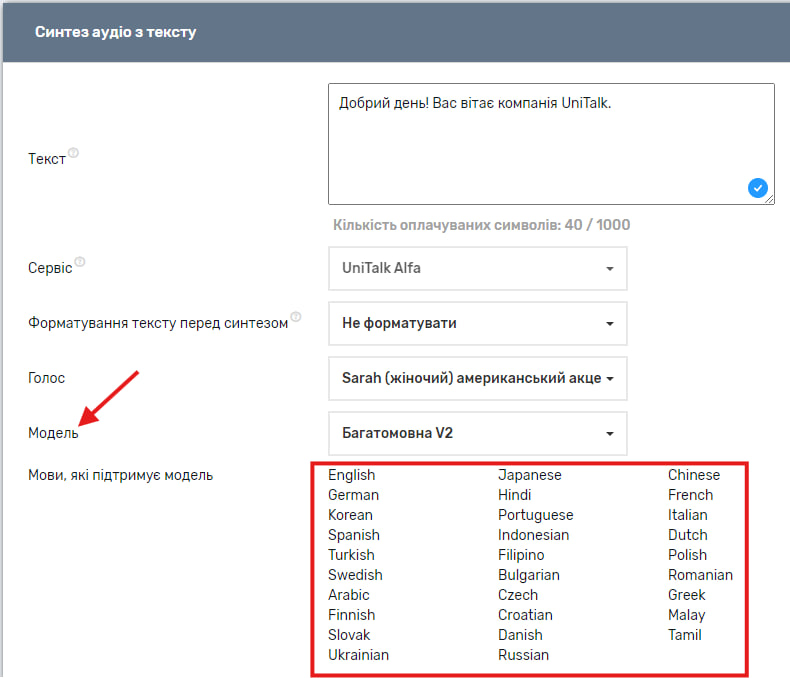
Варто зазначити, що в сервісі UniTalk Alfa також доступний вибір моделі і більша кількість підтримуваних мов.
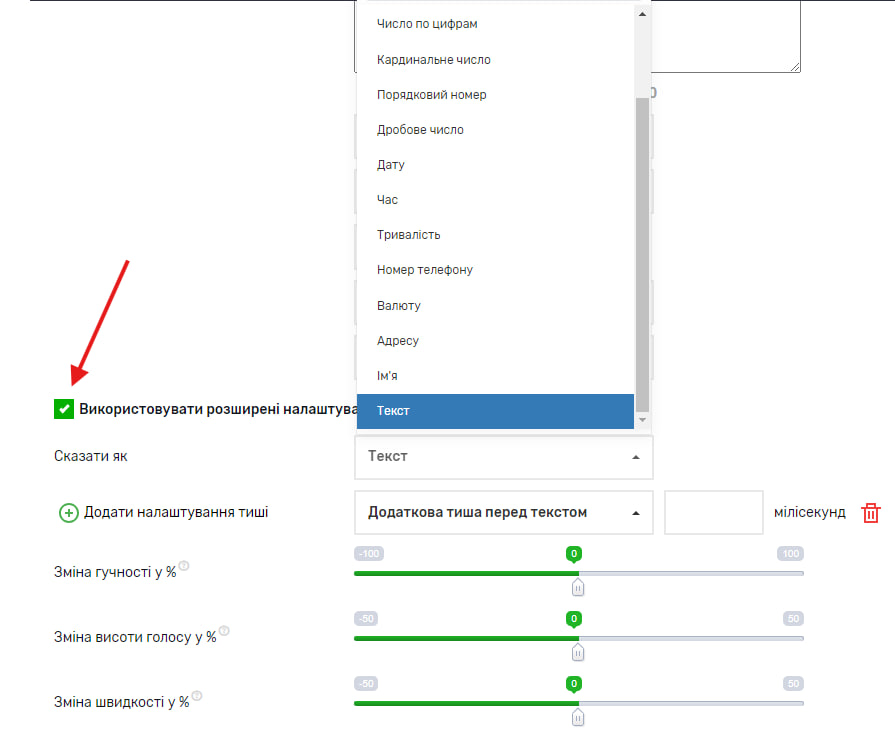
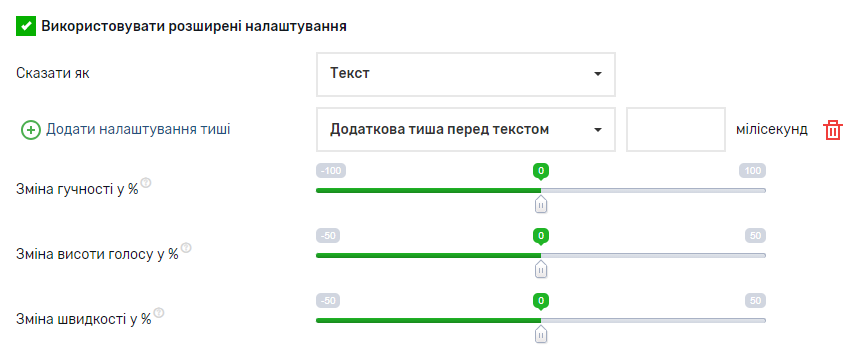
Однією з переваг синтезу мови є можливість використання розширених налаштувань. До таких налаштувань входять: додавання тиші перед текстом, після тексту, перед розділовими знаками, між реченнями, також можливість змінити гучність або висоту, що дозволить голосу звучати нижче або вище, можливість зміни швидкості прочитання тексту. Крім цього, можна обрати варіант того як саме буде промовлятися введена Вами фраза: як адреса, валюта, номер телефону, час, дата і тд.
Всі ці налаштування допоможуть Вам максимально якісно і наближено до реального людського голосу синтезувати Ваш текст.
Зручно також те, що Ви можете одразу побачити вартість тексту, який бажаєте синтезувати.
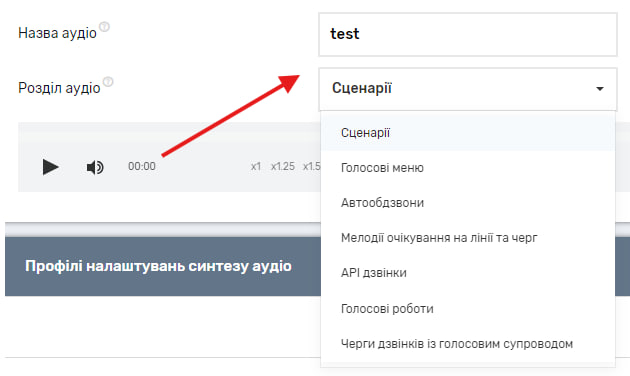
Після того як Ви ввели текст для синтезу, внесли всі необхідні налаштування і натиснули на “Синтезувати”, Вам необхідно ввести назву аудіо і обрати розділ до якого воно буде додано. Важливо обрати саме той розділ, в якому Ви це аудіо збираєтеся застосовувати. Якщо Ви, наприклад, додасте його в розділ “Сценарії”, в інших розділах воно буде недоступне.
Переглянути список віх аудіофайлів, а також розділи, в які вони були додані Ви можете в розділі “Аудіофайли” в особистому кабінеті.
2. Синтез мови в автообдзвонах і предиктивних обдзвонах
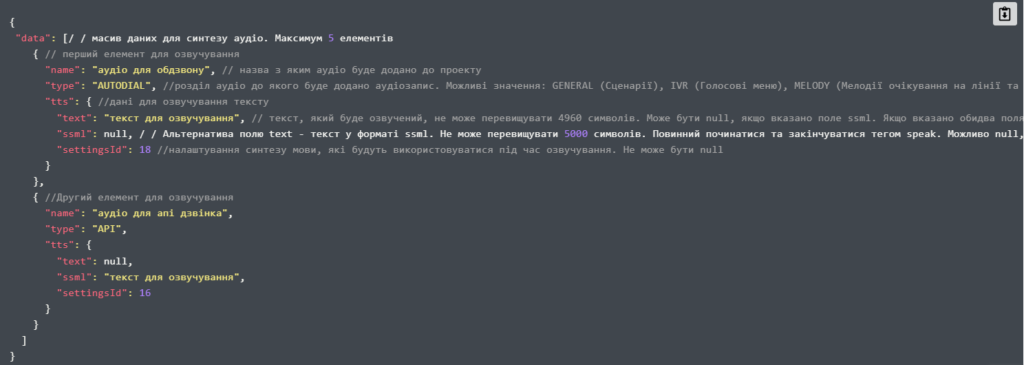
Налаштування синтезу мови доступне також в автообдзвонах. Якщо Вам потрібно при обдзвоні різним абонентам відтворювати різні або частково різні аудіо, Ви можете додати номери для обдзвону разом зі списком аудіо (id аудіо або текст для озвучення) – до 5 аудіо, максимум 2 з яких можуть бути синтезовані з тексту або SSML. Якщо для номера дзвінка вказано текст для озвучення, аудіо буде синтезовано перед початком дзвінка. Такі аудіо не відображаються у списку аудіозаписів проєкту та зберігаються 1 тиждень після завершення дзвінка або максимум 3 місяці. Додати номер в обдзвон разом зі списком аудіо можна двома способами:
1. Через API (документація методу ADD_CALLS)
2. При додаванні номерів з файлу xlsx (з колонками audio1, audio2, audio3, audio4, audio5) на сторінці дзвінків.
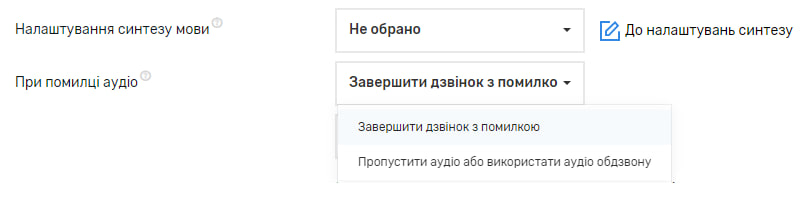
Синтез аудіо в такому випадку відбувається буквально під час дзвінка, тому в разі, якщо сталася помилка під час синтезу аудіо, є можливість обрати: дзвінок завершиться зі статусом “Помилка аудіо” або буде використовуватися загальне аудіо обдзвону.
3. Синтез мови в АРІ дзвінках
В АРІ дзвінках також є можливість синтезу аудіо. При ініціюванні АРІ дзвінка можна вказати список аудіо вписавши id аудіо або текст, який буде озвучено. Можна обрати до 5 аудіо, максимум 2 з яких можуть бути синтезовані з тексту або SSML. Якщо вказаний текст для озвучування, то аудіо буде синтезуватися перед початком дзвінка.
Приклад JSON запиту:
Приклад відповіді:
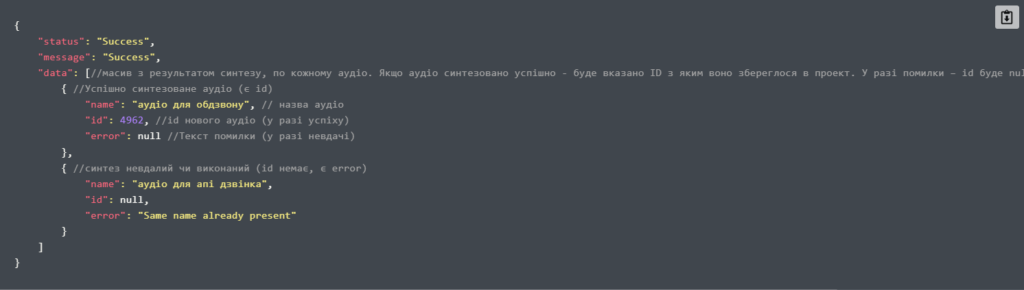
4. Сервіси синтезу мови
Наразі, Ви можете скористатися сервісами для синтезу мови від Microsoft, Google, Yandex, UniTalk Alfa.
Сервіси синтезу мови від Microsoft, Google, Yandex і UniTalk Alfa, мають багато спільного, але також відрізняються за низкою параметрів, включаючи якість голосів, підтримувані мови, можливості кастомізації, та ціною.
1. Microsoft
- Підтримка мов: Microsoft підтримує 9 мов, таких як: Українська, Російська, Англійська (США), Англійська (Великобританія), Чеська, Польська, Італійська, Румунська, та Угорська, пропонуючи як мінімум кілька варіантів голосів для кожної мови.
- Якість голосів: Використовує нейронні мережі для створення високоякісних та природних голосів. Також є можливість кастомізації голосів для конкретних завдань.
- Функціональність: Сервіс пропонує функції зміни стилю вимови, швидкості, та гучність мовлення, а також змінювати висоту голосу. Крім того, є можливість вказати умови тиші при зачитуванні тексту.
2. Google
- Підтримка мов: Google, так само як Microsoft підтримує 9 мов, таких як: Українська, Російська, Англійська (США), Англійська (Великобританія), Чеська, Польська, Італійська, Румунська, та Угорська, пропонуючи як мінімум кілька варіантів голосів для кожної мови, але значно більше за Microsoft.
- Якість голосів: Google використовує передові нейронні мережі для створення голосів високої якості. Останні моделі, такі як Tacotron 2, досягли значного рівня природності.
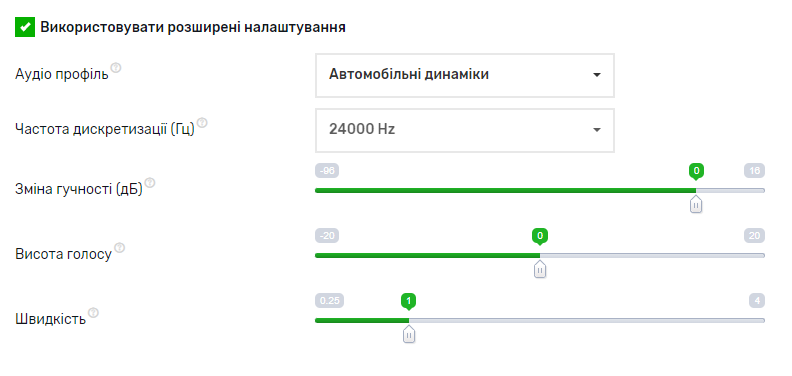
- Функціональність: Google пропонує налаштування голосу, такі як зміна швидкості, висоти, та гучності. Також є можливість встановити профіль звукових ефектів, що накладаються на аудіо, та зазначити Частоту дискретизації (Гц).
3. Yandex
- Підтримка мов: Yandex підтримує лише дві мови включаючи російську, та англійську. Це робить його менш гнучким в порівняні з іншими сервісами.
- Якість голосів: Яндекс використовує нейронні мережі для створення голосів, що досить природні, особливо для російської мови. Якість голосів оптимізована для російськомовного акценту, та вимови.
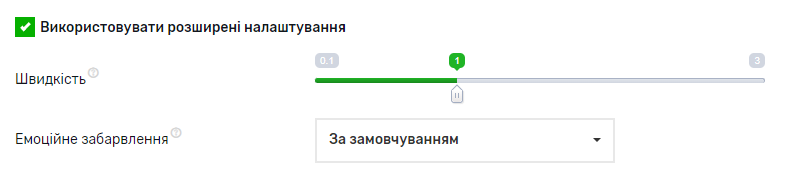
- Функціональність: Сервіс пропонує можливості для зміни швидкості, та може імітувати емоційні відтінки.
4. UniTalk Alfa
- Підтримка мов: UniTalk Alfa, підтримує 31 мову, та різні акценти. Відкривайте нові горизонти комунікації з багатомовною підтримкою, яка охоплює найбільш поширені мови світу, та акценти для кожної з них.
- Якість голосів: Завдяки високоякісному синтезу мови, “UniTalk Alfa” досягає максимальної натуральності та природності звучання, що важко відрізнити від живого голосу. Незалежно від того, чи потрібен вам офіційний тон для бізнесу, чи емоційний стиль для реклами, UniTalk Alfa забезпечить точне відтворення бажаного голосу.
- Функціональність: Сервіс пропонує регулювання стабільності, інтенсивності стилю, чіткості та подібності вимови дозволяє створювати індивідуальні рішення під будь-які потреби. Підтримка унікальних налаштувань, що дозволяють домогтися максимальної реалістичності звучання, яка не поступається живому голосу

Синтез мови — це ключовий інструмент для сучасної автоматизації, що економить ваш час та бюджет. Завдяки гнучким налаштуванням (SSML, паузи, висота) і можливості вибору серед провідних провайдерів (включно з багатомовною та реалістичною UniTalk Alfa), ви можете створювати аудіофайли, які практично не відрізняються від запису професійного диктора. Використовуйте цю технологію для миттєвої персоналізації масових обдзвонів, оновлення IVR-меню та забезпечення безперебійної та натуральної комунікації з клієнтами.


